See it in action
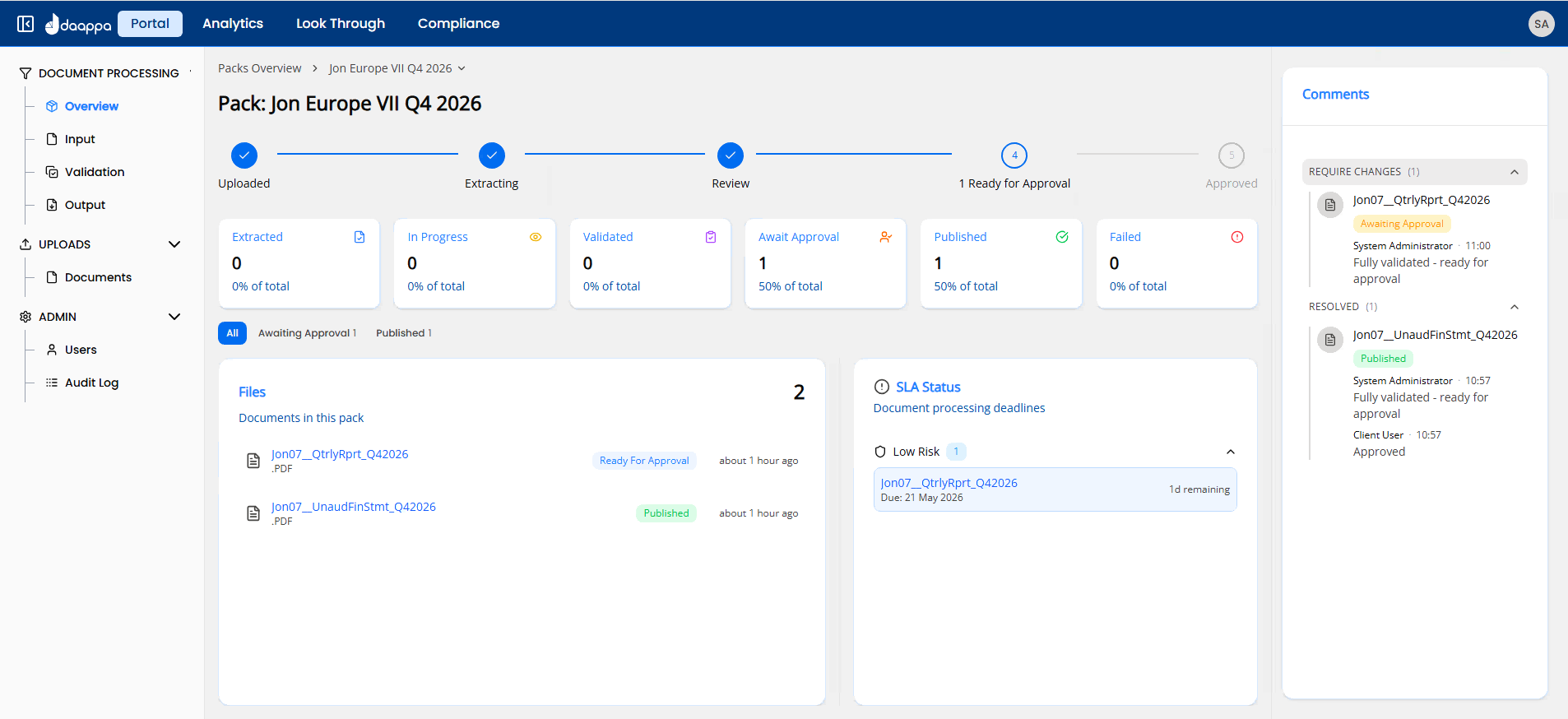
Validation in action
Every extracted value linked back to its source document, with human review on exceptions.
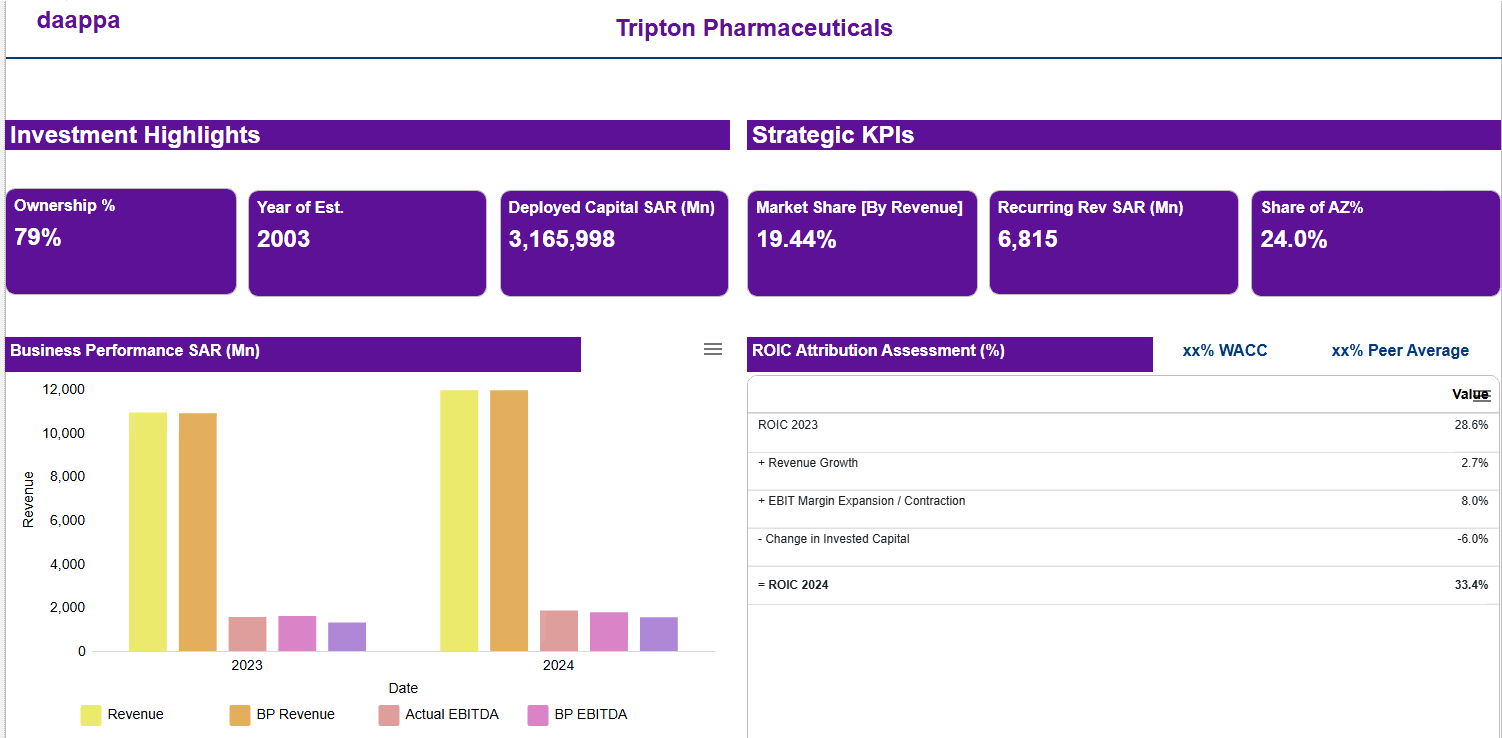
Extractor AI turns quarterly portco reports, GP performance reports, capital account statements, financial documents, and LP letters into structured, validated, analytics-ready data. No re-keying. No spreadsheet bridges. Full audit trail back to the source document.
Every GP structures their quarterly report differently. Every financial statement uses different table formats, calculation conventions, and terminology. Extraction alone cannot solve this -- data must be structured, reconciled, and calculated consistently before it can be used.
Most AI extraction tools rely on a single large language model. That works for simple, consistent documents. It doesn't work for the messy, inconsistent, narrative-heavy documents that private markets produces.
Four stages. Every document moves through the same controlled pipeline. Click a stage to see what happens at each step.
To ensure consistency and auditability, Extractor AI separates three distinct layers. Each layer has its own controlled logic. Nothing bleeds between them.
Extractor AI offers three service tiers. You can start with extraction only and upgrade as your confidence and requirements grow.
Extractor AI preserves four distinct stages of the data pipeline. At any point you can trace any value back to the exact location in the original document.
Every data point extracted by Extractor AI is linked directly to the source location in the original document. Users can view the extracted value in context, trace the field back to the source table or text section, and verify the original document reference.
This is not a summary or a reference number. It is a direct visual link between the value in your dataset and the cell, row, or paragraph it came from.
For firms that want daappa's operations team to handle first-level validation, enrichment, and exception handling, Tier 2 provides a managed service with agreed turnaround times and full client visibility throughout.
The Extractor AI proof of concept is designed to deliver results against your actual documents -- not a generic demo. You test on your real reports, with your real schemas, and measure against your current process.
Tell us about the documents you process, the schemas you use, and what the current process costs you in time. We will design a proof of concept around your actual quarterly cycle.
Run daappa in our cloud, your cloud, or entirely on-premise inside your own environment. Your data is never shared with external AI engines unless you choose to. Built for enterprises and regulated managers who run their own AI and data infrastructure, or who simply cannot let client data leave their control.